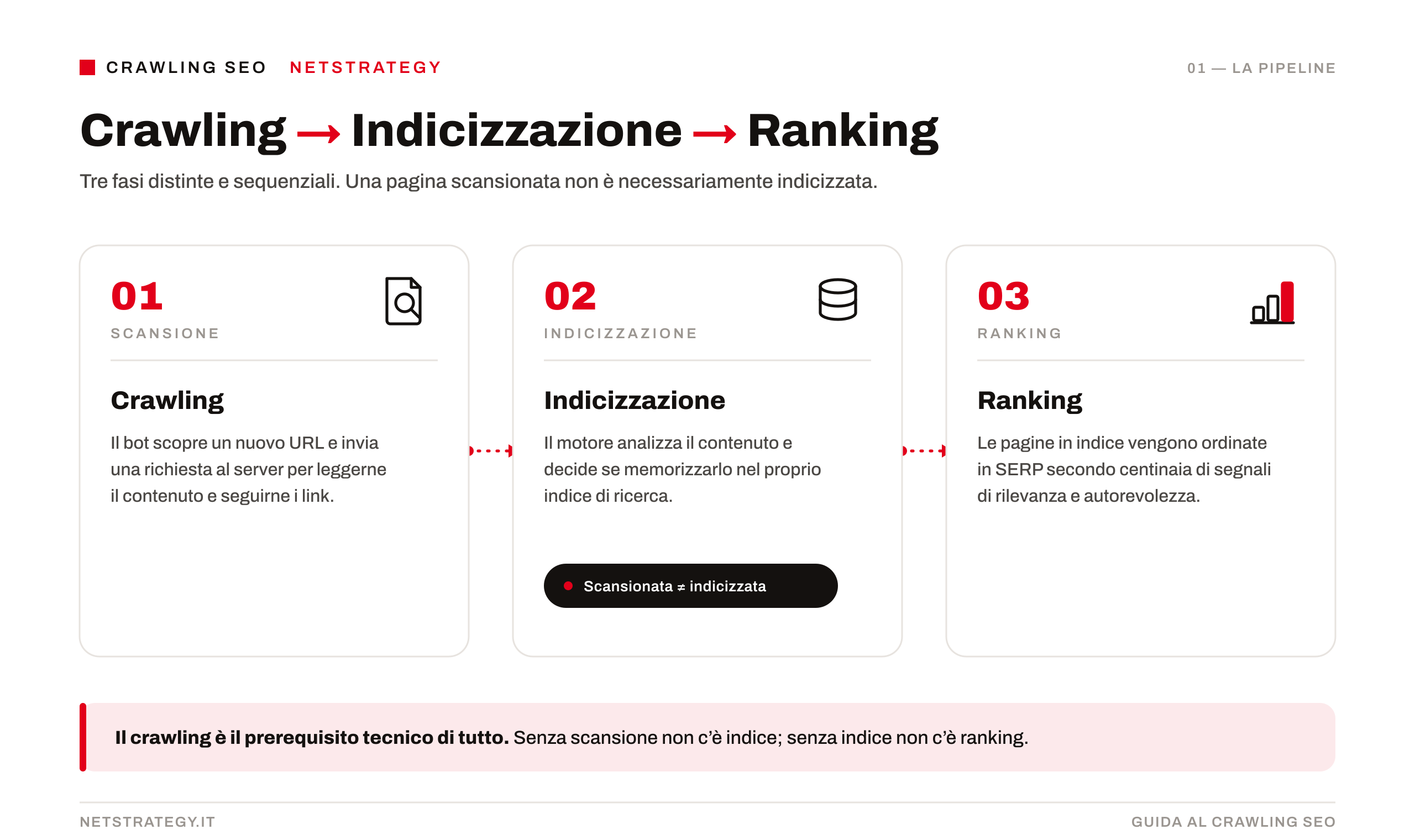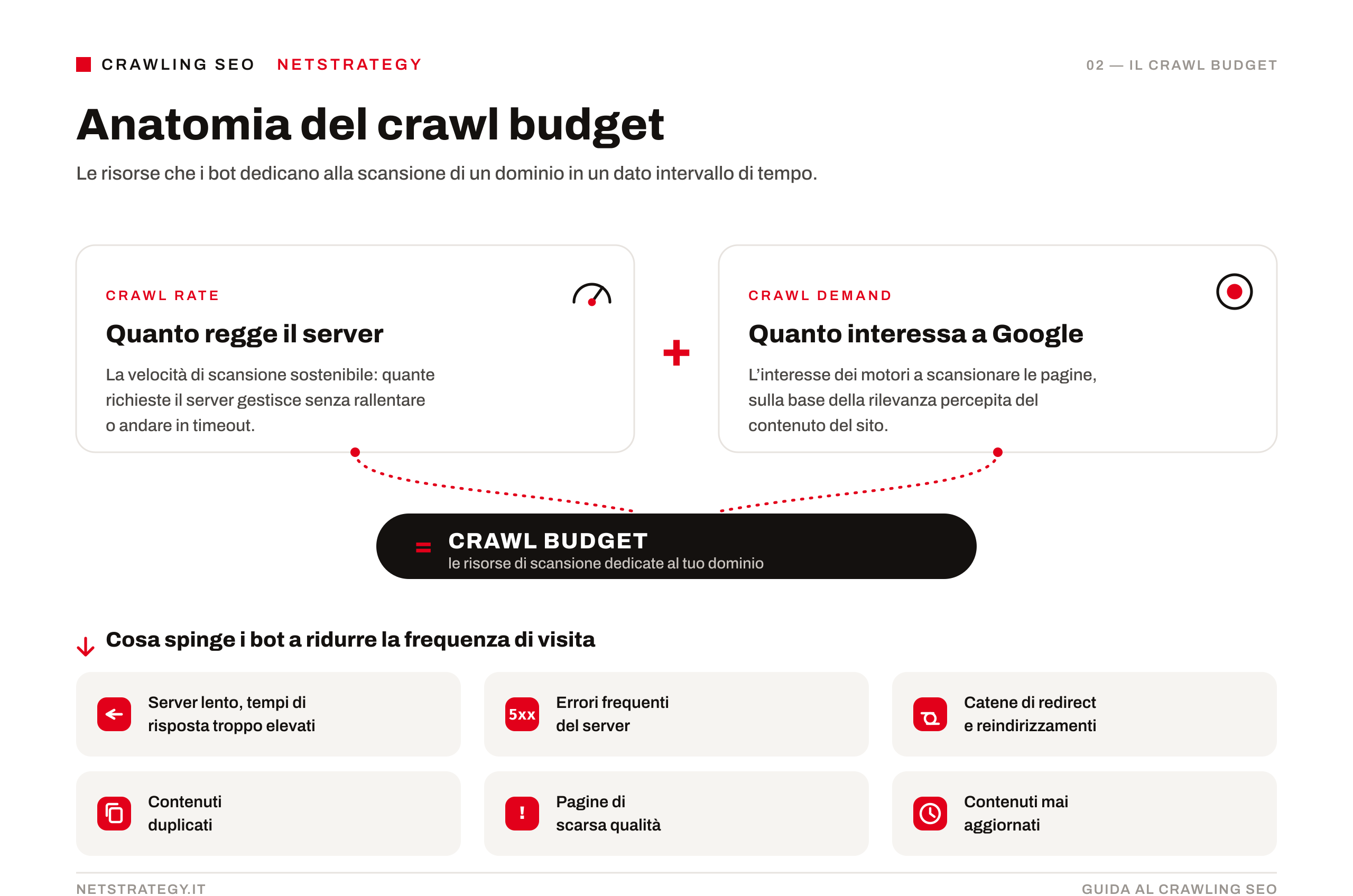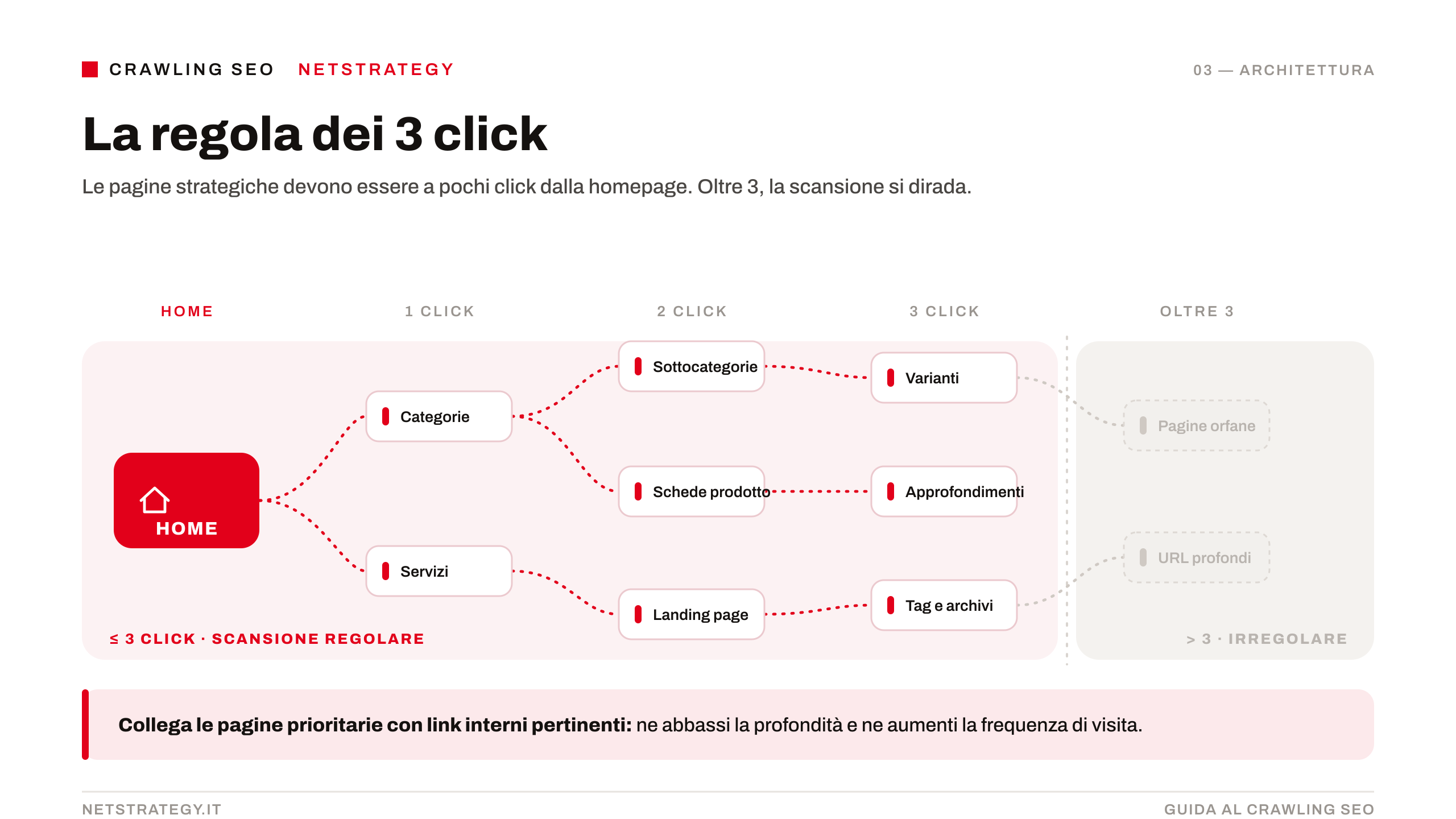
Il crawling SEO è il processo attraverso cui i motori di ricerca esplorano il web navigando tra i collegamenti ipertestuali per scoprire, leggere e catalogare nuovi contenuti. Una pagina non esiste nei database dei motori di ricerca se prima non viene scansionata correttamente. Senza questa fase ogni sforzo o investimento per la visibilità risulta inefficace.
A eseguire questa importante operazione sono i crawler, detti anche spider o bot. Googlebot, il crawler ufficiale di Google, percorre costantemente miliardi di URL seguendo i link da una pagina all'altra, registrando il contenuto e inviando i dati ai server di Google per l'elaborazione successiva.
Distinguiamo subito due utilizzi distinti della stessa tecnologia:
Crawling SEO | Crawler web scraping |
| Scansione orientata all'indicizzazione organica, eseguita dai bot ufficiali dei motori di ricerca per valutare e posizionare i contenuti. | Strumento progettato per estrarre e copiare massivamente dati da siti web, spesso a fini commerciali o analitici, senza relazione diretta con il posizionamento sui motori di ricerca. |