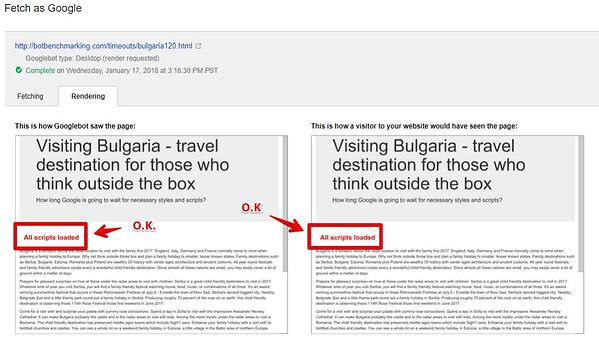
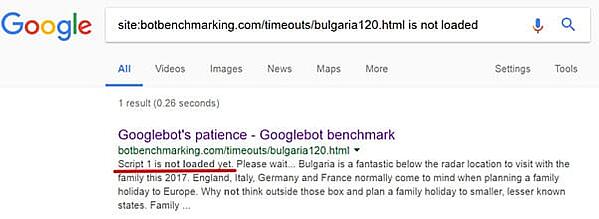
HTML e JavaScript sono completamente differenti per ciò che riguarda la gestione degli errori. Un singolo errore nel tuo codice può rendere Google incapace di fare il rendering della tua pagina.
Per citare Mathias Schäfer, l’autore dell’e-book “Robust JavaScript”:
“The JavaScript parser is not that polite. It has a draconian, unforgiving error handling. If it encounters a character that is not expected in a certain place, it immediately aborts parsing the current script and throws a SyntaxError. So one misplaced character, one slip of the pen can ruin your script.”
“Il parser JavaScript non è così gentile. È dotato di un sistema di gestione dell’errore draconiano e intransigente. Se si ritrova in presenza di un carattere che non è previsto in una determinata posizione, l’analisi dello script viene immediatamente interrotta a causa di un errore di sintassi. Dunque, basta un carattere sbagliato, un solo passo falso, per rovinare tutto il tuo script.”
A volte lo sviluppatore compie errori
Potresti aver sentito parlare dell’esperimento jsseo.expert che Bartosz Góralewicz, CEO di Onely, ha condotto per verificare la capacità di Google nel gestire siti web costruiti usando alcuni dei framework JavaScript più comuni.
All’inizio, è risultato che Googlebot non era in grado di renderizzare Angular 2. Un risultato insolito, dal momento che Angular è stato creato dal team di Google; così Góralewicz ha cercato di spiegare questo fenomeno:
“And it turned out that there was an error in Angular 2’s QuickStart, a kind of tutorial for how to set up Angular 2-based projects, which was linked in the official documentation. All that research to discover that the Google Angular team had made a mistake. On April 26, 2017, that mistake was corrected.”
“Si è scoperta la presenza di un errore nel QuickStart di Angular 2, una sorta di tutorial per imparare a creare progetti basati su Angular 2, linkato all’interno della documentazione ufficiale. Tutta quella ricerca per scoprire che il team di Google Angular aveva commesso un errore. Il 26 aprile 2017 quell’errore è stato corretto.”
Infine, in seguito alla correzione degli errori, è stato possibile indicizzare un sito di prova costruito con Angular 2, insieme a tutto il suo contenuto. Questo esempio illustra perfettamente la situazione che si verifica quando un singolo errore impedisce al Googlebot di renderizzare una pagina. Bisogna sottolineare che l’errore non è stato commesso da sviluppatori alle prime armi. Tutt’altro: è stato fatto dagli stessi developer che hanno contribuito allo sviluppo di Angular, il secondo framework JavaScript in ordine di popolarità.
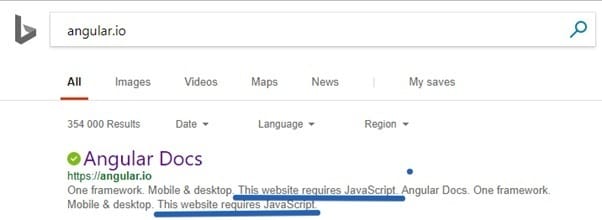
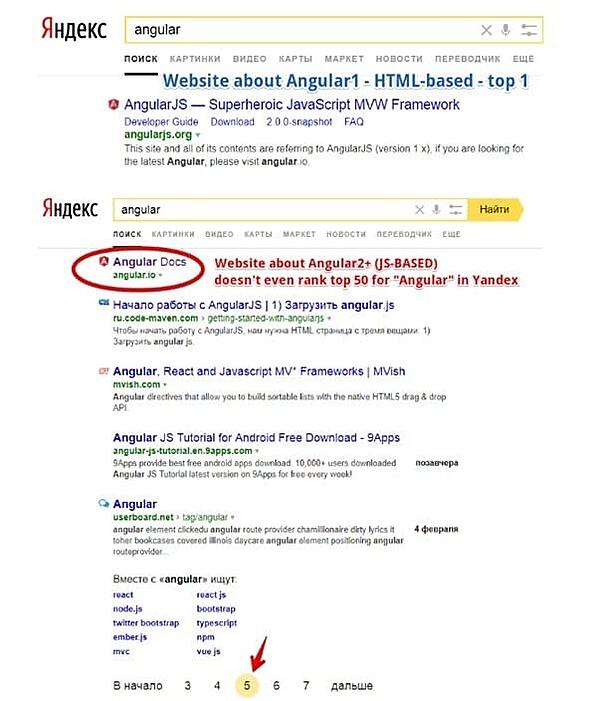
Gli esempi, ad ogni modo, non si limitano a questo. Vediamone un altro, particolarmente indicativo. Nel dicembre del 2017, Google ha deindicizzato alcune pagine di Angular.io (un sito web Javacript renderizzato lato client e basato su Angular 2+). La domanda sorge spontanea: perché l’ha fatto? La ragione è sempre la stessa: un singolo errore nel codice ha reso impossibile renderizzare la pagina e ciò ha causato un’enorme deindicizzazione.
L’errore, da allora, è stato corretto. Igor Minar di Angular.io ha spiegato che:
“Given that we haven’t changed the problematic code in 8 months and that we experienced significant loss of traffic originating from search engines starting around December 11, 2017, I believe that something has changed in crawlers during this period of time which caused most of the site to be de-indexed, which then resulted in the traffic loss.”
“Dal momento che il codice che presentava problemi non è stato modificato in 8 mesi e che abbiamo registrato una rilevante perdita di traffico proveniente dai motori di ricerca intorno all’11 di dicembre 2017, credo che in questo periodo di tempo sia cambiato qualcosa nel funzionamento dei crawler, il che ha causato la deindicizzazione di gran parte del sito, che si è poi tradotta in perdita di traffico.”
Porre rimedio al suddetto errore di rendering su Angular.io fu possibile grazie a un esperto team di sviluppatori JavaScript e all’implementazione di un sistema di segnalazione degli errori. La correzione ha permesso di far nuovamente indicizzare le pagine che avevano presentato il problema.